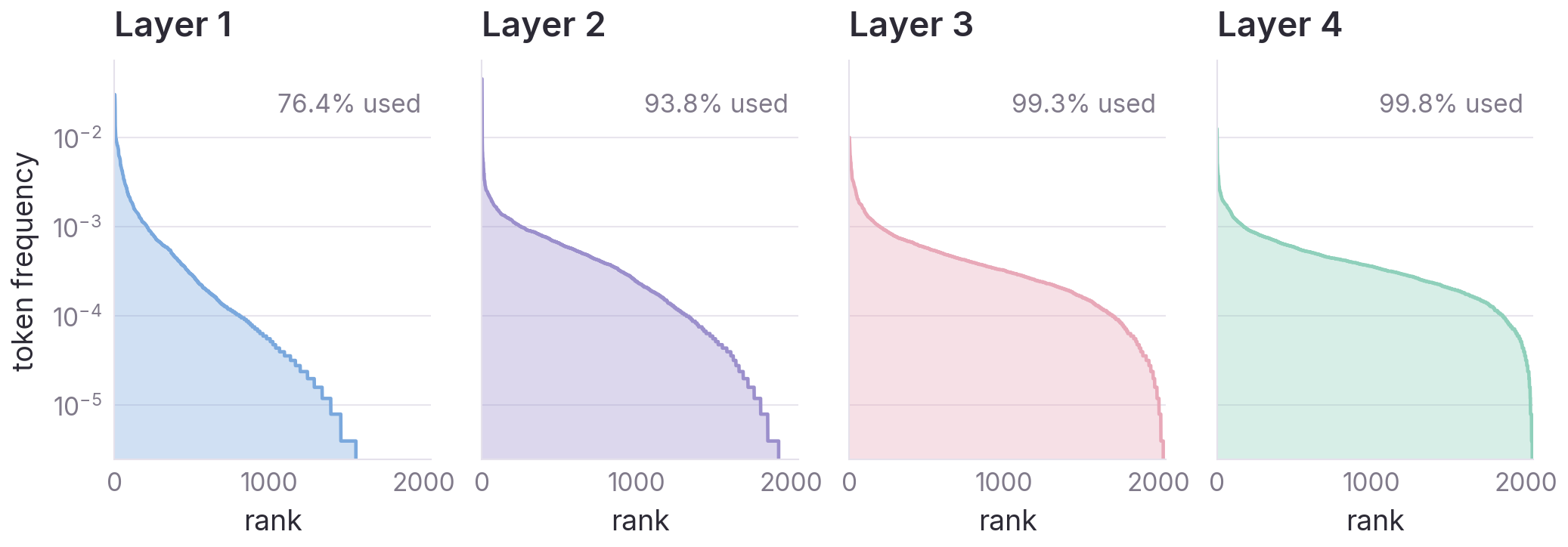
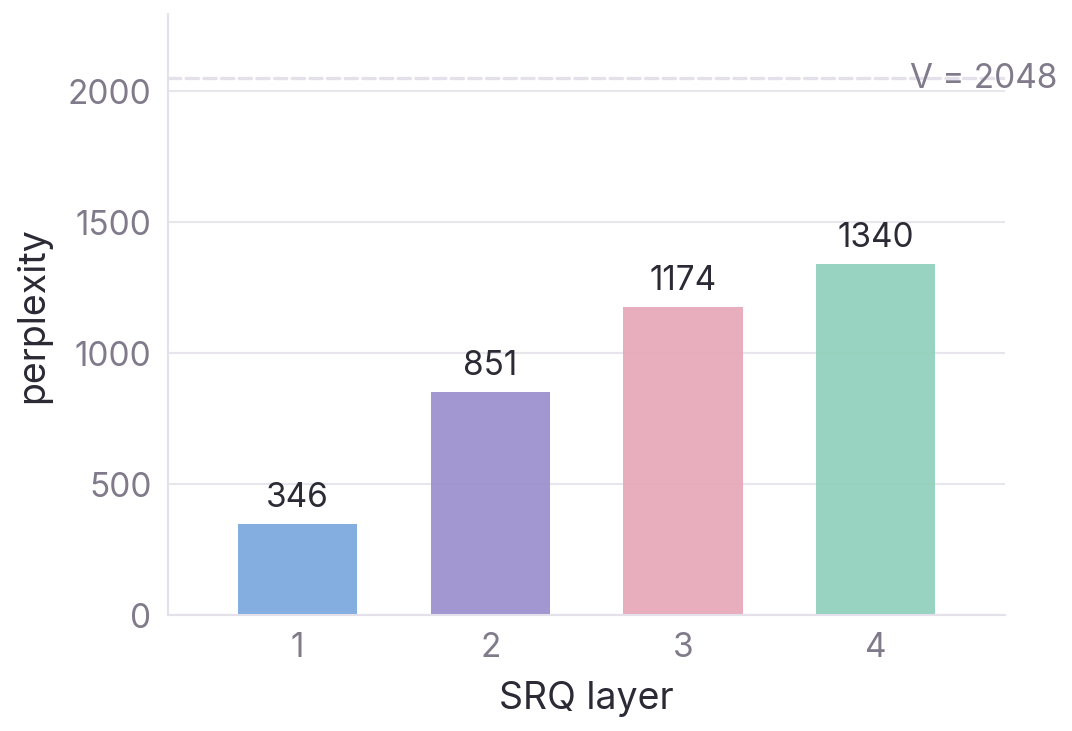
Existing action tokenizers compress motion into discrete codes — but the codes are opaque to the surrounding vision-language model. X-Tokenizer reframes tokenization as semantic interface learning: we co-train a multimodal encoder, a Semantic Residual Quantizer (SRQ), and a paired decoder so that the top-level codes q₀ are simultaneously grounded in language and faithful to motion.
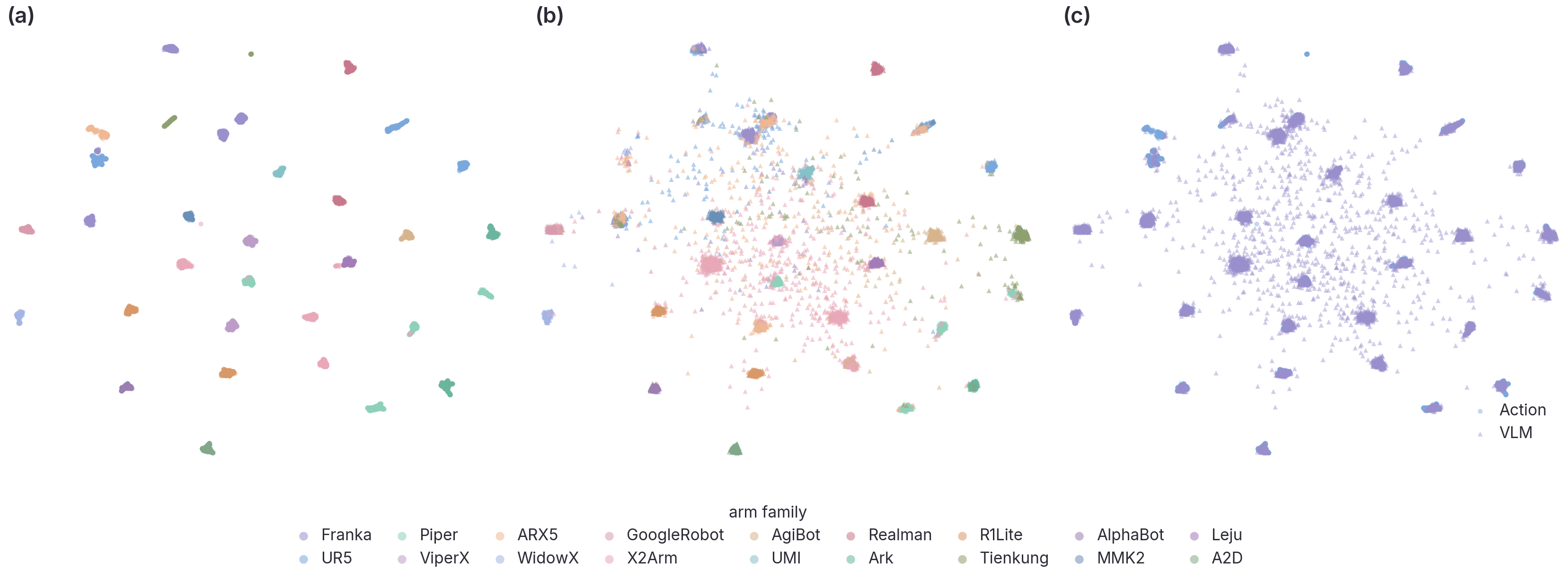
Pretraining at scale — 2.4 M trajectories, 2.0 B action frames, 17 arm families — yields one frozen tokenizer that reuses across (i) RoboTwin 2.0 dual-arm benchmarks, (ii) 5-arm cross-embodiment joint training, and (iii) real-world tabletop manipulation, while leaving the host VLM's reasoning ability intact.
On RoboTwin Hard the dual-arm setting degrades only −3.8 (vs. −5.9 for π0.5). Cross-embodiment joint training lifts Hard by +10.4. Real-world average is 77.4 across 7 tasks with no per-task tuning. Against FAST, multimodal grounding gains +13.5 % and long-horizon execution gains +8.25.